Dance Control
Here we start with a typical image generated with Stable Diffusion. As you might guess, the prompt involves the future, some dancers, and some painters.
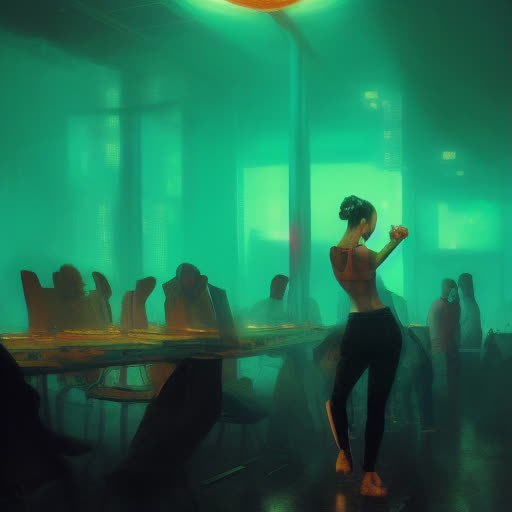
We used RunwayML to extract depth data from a video sequence, and the results look like this.

Feeding that into Stable Diffusion with ControlNet set up for depth, we get a very different image. For this post, we are using the popular, and super convenient, Stable Diffusion web UI.
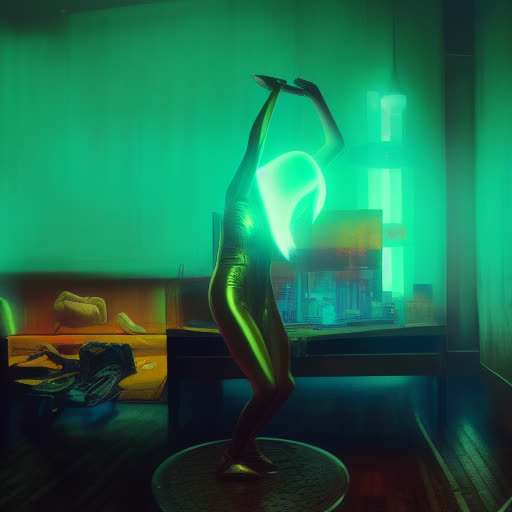
The original video was shot indoors, and we can also use RunwayML to create a mask and remove the depth image background, letting the model hallucinate its own setting. Conveniently, we also acquire a third arm.
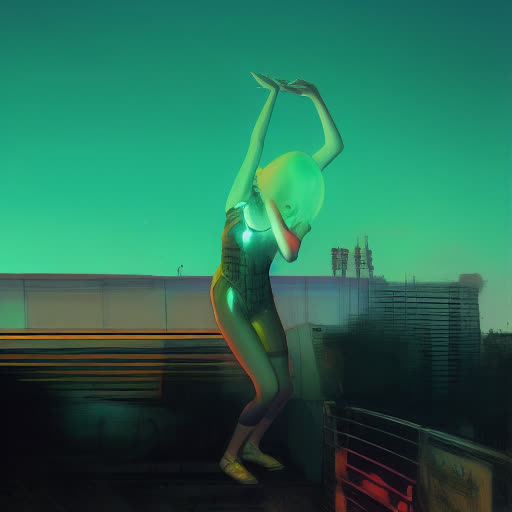
We can also swap in a different background, for more control and variety there.

In the end, we found that simply using After Effects to composite the dancer onto a background, and using the depth_midas preprocessor obviated the need for computing the depth map ourselves, and instead of composing depth maps, we just let the model estimate the depth of a composite image and use this for the ControlNet depth input. The result is below.
The keen-eyed readers among you will of course have noticed the source of the background, a animation created with Cinema4d all those aeons ago.